×

香港科技大学(广州)- 安必平
医疗数据智能联合实验中心
HKUST(GZ)-LBP
Medical Data Intelligence Joint-Lab
mdi.hkust-gz.edu.cn
Contact us: cao@ust.hk
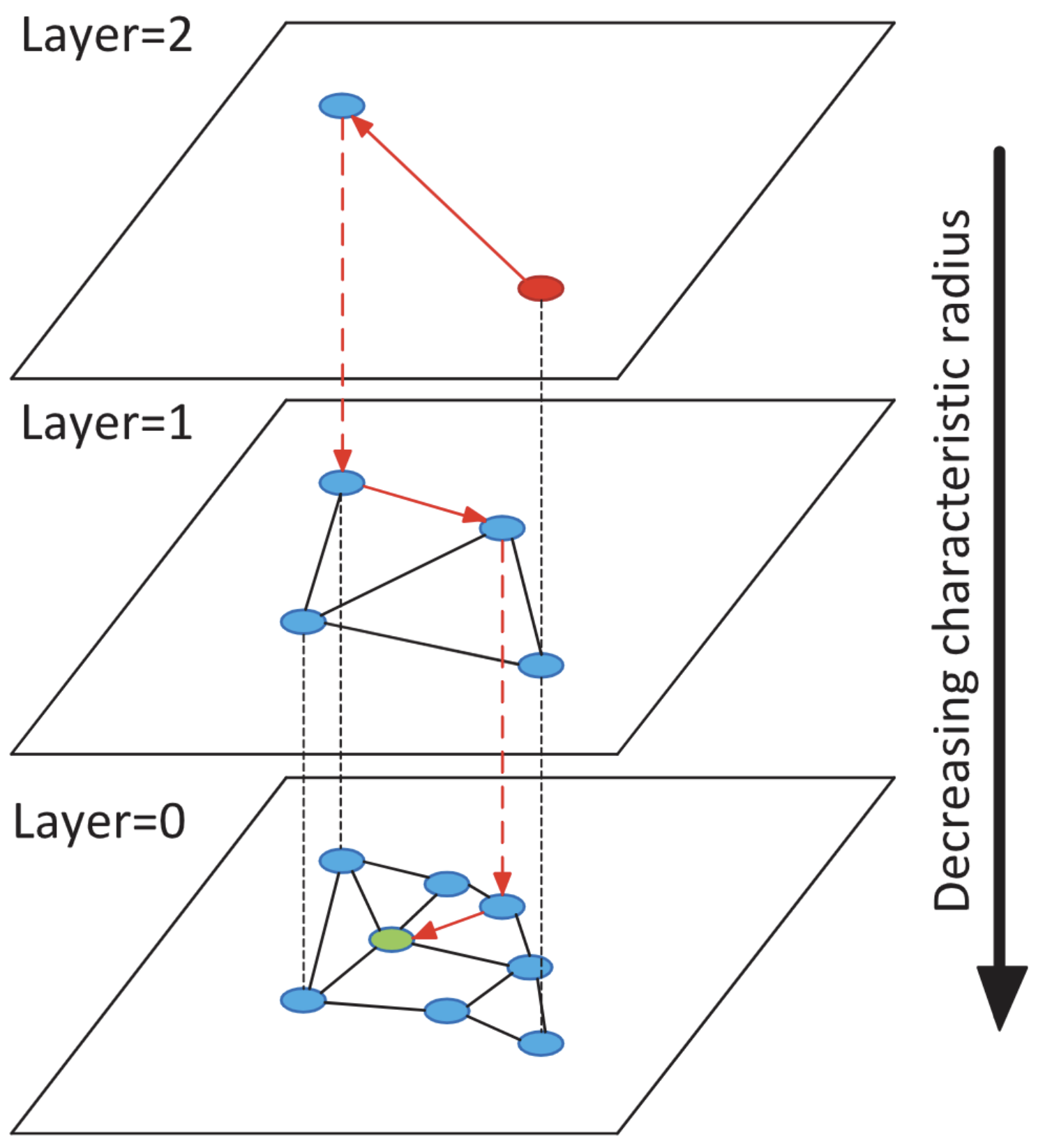
向量检索及GPU加速
探讨向量检索技术的发展,从传统的CPU索引方法到现代GPU加速方案。重点介绍近似最近邻搜索(ANNS)中的多种经典算法及其在大规模数据处理中的应用,特别是在医疗领域的快速语义搜索和实时决策支持方面的关键作用。
向量检索
GPU加速
ANNS
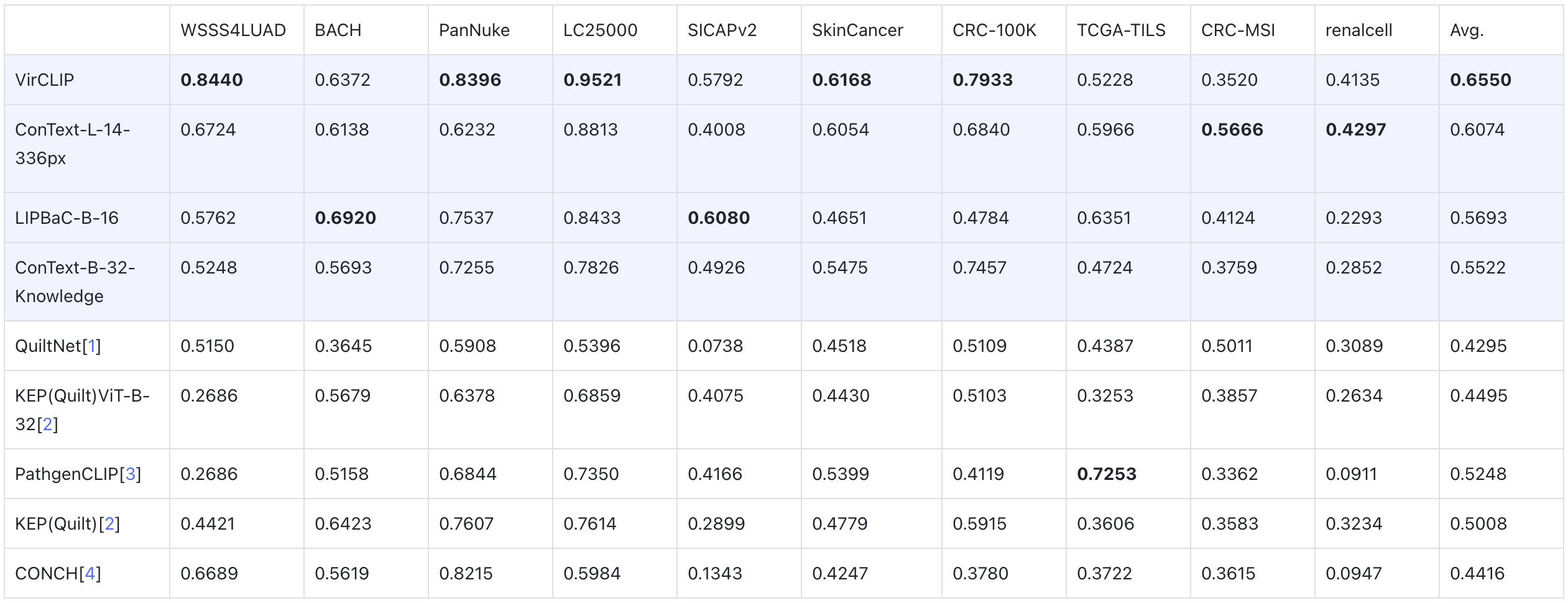
CLIP
数据集
测试方法
病理多模态数据集中的非病理图像过滤
现有公开病理图文配对数据集(如Quilt-1m)通过截取YouTube视频片段构建,尽管已实施初步过滤策略,但仍存在显著噪声(如非病理图像)。基于不同数据规模与模型架构的分类器训练表明,各类模型在分类性能上存在显著差异。实验验证表明,通过过滤非病理数据构建的优化数据集对大模型进行微调,能够显著提升其在下游任务上的表现。
数据清洗
数据过滤
Domain-specific
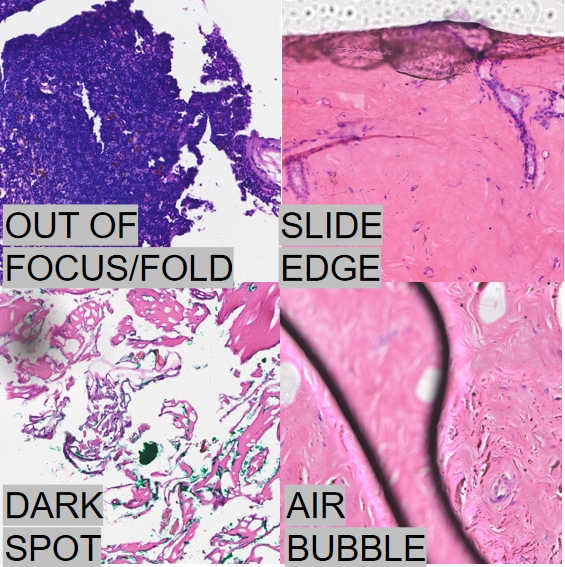
无需训练的病理图像块质量控制方法
病理数字切片的制作流程涉及多个关键环节,其中任一环节的潜在质量问题均可能引发图像失焦、组织重叠等缺陷。这些异常区域会导致病理组织结构信息缺失,严重影响临床诊断的准确性和可靠性。因此,亟需建立一种快速、高效的算法模型,实现问题区域的精准识别与过滤,并深入探究此类低质图像块对病理智能分析模型训练的干扰机制及其影响程度。
质量控制
数据过滤
Training-Free
非病理图像过滤
数据滤波以获得滤除噪声高的数据。
专有领域
数据过滤
乳腺癌中的多模态大模型评估
评估多模态大型语言模型(MLLMs)在乳腺癌任务中的表现。
乳腺癌
基准测试
MLLM
病理学的缩放定律
该项目旨在经验性地验证一个假设,即增加训练数据量显著提升了病理学特定基础模型的性能能力,特别是那些整合了视觉和语言理解的模型。
缩放
视觉-语言模型
MLLM
基于CLAM的图像描述生成
基于CLAM的现有能力对WSI图片进行弱监督-少样本的标注。
标注
CLAM
CLIP
基于知识库增强的病理学CLIP(公共数据集)
基于知识库增强的病理学CLIP致力于解决病理学基础模型在不同病理学领域性能变化的问题。
知识图谱
CLIP
MLLM
论文
病理图像过滤
我们的研究专注于构建一个全面的基准来评估其性能。
乳腺癌
基准测试
MLLM

图像描述数据市场演示
一个新颖的、公平且基于质量的数据市场FQora
数据市场
平衡帕累托优化
多目标优化
基于GraphRAG的病理学大语言模型
利用大型语言模型(LLM)对私有病理数据进行深度挖掘与分析,通过构建精细化的知识图谱,整合病理学领域内的丰富信息。
知识图谱
MLLM
GraphRAG
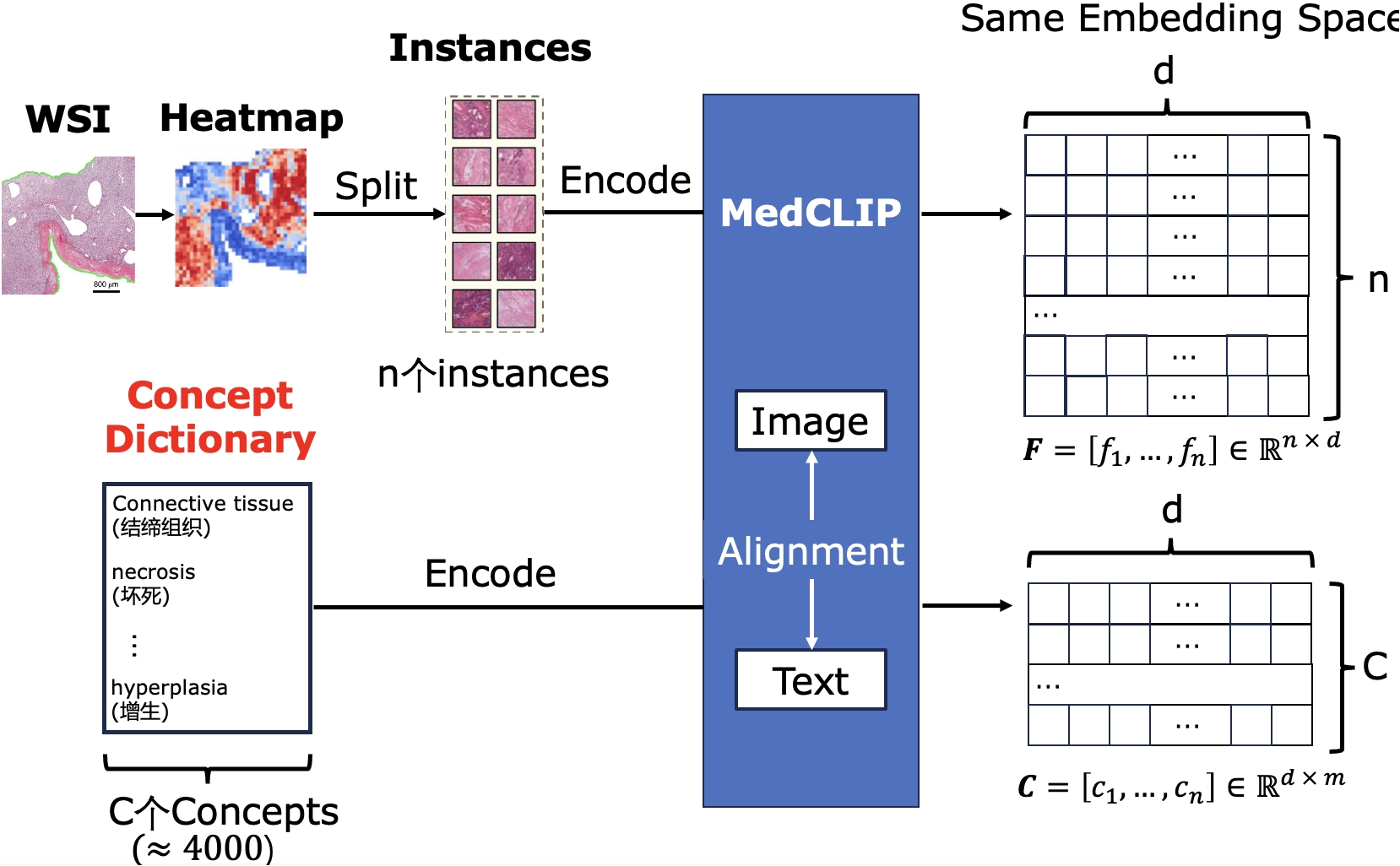
基于多实例学习的病理图文结构化对齐
通过海量病理文本对训练出的病理基础模型提供了强大的病理图文对齐能力。
多实例学习
WSI表示学习
病理图像与文本对齐
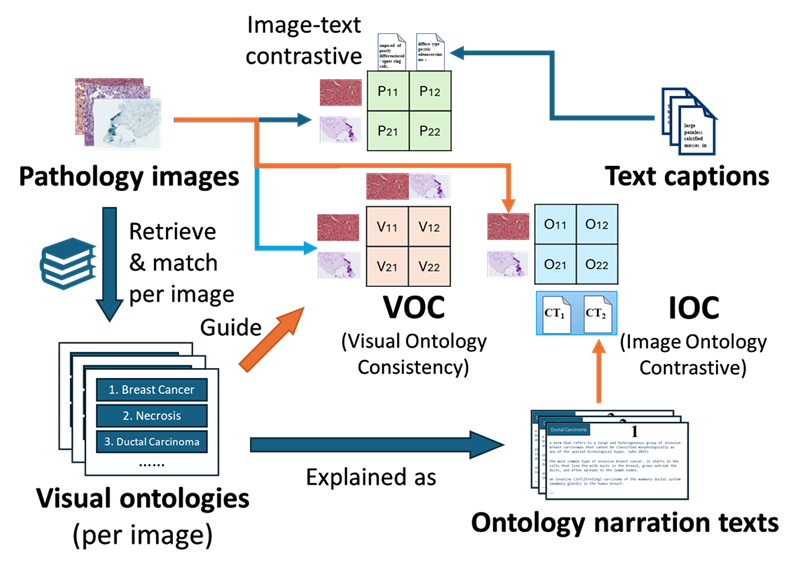
Pivot:用病理知识库增强病理图文对齐
对齐病理图像、病理条目和文本。
病理学
多模态
知识注入
RIVL:通过插值法解决在病理图文对齐中遇到的模态缺失问题
根据与候选图片最相似的数张图片来推导出该图片的文本标注语义向量。
病理学
多模态
重采样
Keywords
- 知识图谱
- 专有领域
- 数据过滤
- 乳腺癌
- MLLM
- 视觉-语言模型
- 标注
- GraphRAG
- 数据市场
- 平衡帕累托优化
- 多目标优化
- 基准测试
- CLIP
- 缩放
- 向量检索
- GPU加速
- ANNS
- 数据集
- 测试方法
- 质量控制
- Training-Free
- 论文
- 显示全部